Read Output of Javascript Script Rvest R
Tutorial: Web Scraping in R with rvest
Published: Apr 13, 2020

The net is ripe with data sets that you can employ for your own personal projects. Sometimes you're lucky and you'll accept admission to an API where y'all can just directly ask for the information with R. Other times, you won't be so lucky, and you won't exist able to become your data in a bang-up format. When this happens, nosotros demand to turn to web scraping, a technique where nosotros get the data we want to analyze by finding it in a website's HTML code.
In this tutorial, we'll cover the nuts of how to do web scraping in R. We'll be scraping data on weather forecasts from the National Conditions Service website and converting information technology into a usable format.
Spider web scraping opens up opportunities and gives usa the tools needed to really create data sets when we can't find the information we're looking for. And since nosotros're using R to practice the web scraping, we can only run our code once again to go an updated data set if the sites nosotros employ get updated.
Agreement a web page
Earlier we can start learning how to scrape a web page, we need to understand how a web folio itself is structured.
From a user perspective, a spider web page has text, images and links all organized in a way that is aesthetically pleasing and easy to read. But the spider web folio itself is written in specific coding languages that are then interpreted by our web browsers. When we're web scraping, we'll need to deal with the actual contents of the spider web page itself: the code earlier it's interpreted by the browser.
The main languages used to build web pages are called Hypertext Markup Linguistic communication (HTML), Cascasing Mode Sheets (CSS) and Javascript. HTML gives a web folio its bodily structure and content. CSS gives a web page its mode and wait, including details like fonts and colors. Javascript gives a webpage functionality.
In this tutorial, nosotros'll focus by and large on how to use R spider web scraping to read the HTML and CSS that make upwards a web page.
HTML
Different R, HTML is not a programming language. Instead, it's chosen a markup language — it describes the content and structure of a spider web folio. HTML is organized usingtags, which are surrounded by <> symbols. Different tags perform different functions. Together, many tags will form and incorporate the content of a spider web page.
The simplest HTML certificate looks similar this:
<html> <caput> Although the above is a legitimate HTML document, it has no text or other content. If we were to salve that equally a .html file and open it using a web browser, we would come across a blank page.
Notice that the word html is surrounded by <> brackets, which indicates that information technology is a tag. To add some more construction and text to this HTML document, we could add the following:
<head> </head> <body> <p> Here'south a paragraph of text! </p> <p> Hither's a second paragraph of text! </p> </body> </html> Here we've added <caput> and <body> tags, which add together more construction to the document. The <p> tags are what we use in HTML to designate paragraph text.
In that location are many, many tags in HTML, but we won't be able to cover all of them in this tutorial. If interested, you tin check out this site. The important takeaway is to know that tags have particular names (html, body, p, etc.) to make them identifiable in an HTML document.
Observe that each of the tags are "paired" in a sense that each one is accompanied by some other with a similar proper noun. That is to say, the opening <html> tag is paired with another tag </html> that indicates the start and end of the HTML document. The aforementioned applies to <trunk> and <p>.
This is important to recognize, because it allows tags to exist nested inside each other. The <body> and <head> tags are nested within <html>, and <p> is nested within <torso>. This nesting gives HTML a "tree-like" structure:
This tree-similar structure will inform how we look for certain tags when we're using R for web scraping, so it'southward important to continue it in mind. If a tag has other tags nested inside information technology, we would refer to the containing tag as the parent and each of the tags within it equally the "children". If there is more than 1 child in a parent, the child tags are collectively referred to as "siblings". These notions of parent, child and siblings give us an idea of the hierarchy of the tags.
CSS
Whereas HTML provides the content and construction of a web page, CSS provides information about how a spider web page should be styled. Without CSS, a web folio is dreadfully manifestly. Here'due south a simple HTML document without CSS that demonstrates this.
When nosotros say styling, nosotros are referring to a wide, wide range of things. Styling tin can refer to the color of detail HTML elements or their positioning. Like HTML, the telescopic of CSS material is and so large that nosotros tin't comprehend every possible concept in the linguistic communication. If you're interested, y'all can learn more than here.
Two concepts we do need to acquire before we delve into the R web scraping code areclasses and ids.
Get-go, allow's talk about classes. If we were making a website, at that place would oftentimes exist times when we'd want similar elements of a website to wait the same. For example, we might desire a number of items in a list to all appear in the same color, red.
Nosotros could accomplish that by direct inserting some CSS that contains the colour information into each line of text's HTML tag, like and then:
<p style="color:blood-red" >Text 1</p> <p style="color:red" >Text 2</p> <p style="colour:red" >Text iii</p> The manner text indicates that we are trying to utilise CSS to the <p> tags. Inside the quotes, we see a key-value pair "color:red". color refers to the color of the text in the <p> tags, while scarlet describes what the color should exist.
But as we can see above, we've repeated this central-value pair multiple times. That's not ideal — if nosotros wanted to change the colour of that text, we'd have to modify each line one by i.
Instead of repeating this style text in all of these <p> tags, nosotros tin replace information technology with a form selector:
<p class="red-text" >Text 1</p> <p class="crimson-text" >Text ii</p> <p form="red-text" >Text three</p> The form selector, we can ameliorate signal that these <p> tags are related in some style. In a divide CSS file, we can creat the scarlet-text form and ascertain how information technology looks by writing:
.red-text { color : cherry-red; } Combining these two elements into a single web folio volition produce the same effect as the first set of red <p> tags, simply it allows us to make quick changes more easily.
In this tutorial, of grade, nosotros're interested in web scraping, non building a spider web page. Just when we're web scraping, we'll often need to select a specific class of HTML tags, so nosotros need empathise the basics of how CSS classes piece of work.
Similarly, we may often want to scrape specific data that's identified using an id. CSS ids are used to requite a single element an identifiable name, much like how a form helps define a class of elements.
<p id="special" >This is a special tag.</p> If an id is attached to a HTML tag, it makes it easier for us to identify this tag when we are performing our actual web scraping with R.
Don't worry if you don't quite empathise classes and ids yet, it'll go more clear when we beginning manipulating the code.
At that place are several R libraries designed to take HTML and CSS and exist able to traverse them to await for particular tags. The library nosotros'll use in this tutorial is rvest.
The rvest library
The rvest library, maintained by the legendary Hadley Wickham, is a library that lets users easily scrape ("harvest") information from web pages.
rvest is 1 of the tidyverse libraries, so it works well with the other libraries contained in the package. rvest takes inspiration from the web scraping library BeautifulSoup, which comes from Python. (Related: our BeautifulSoup Python tutorial.)
Scraping a web page in R
In social club to use the rvest library, nosotros kickoff need to install it and import it with the library() part.
install.packages("rvest") library(rvest) In order to start parsing through a web page, nosotros starting time demand to request that data from the figurer server that contains it. In revest, the role that serves this purpose is the read_html() office.
read_html() takes in a web URL as an argument. Permit's commencement by looking at that simple, CSS-less page from earlier to run into how the part works.
unproblematic <- read_html("https://dataquestio.github.io/web-scraping-pages/simple.html") The read_html() function returns a list object that contains the tree-like structure we discussed before.
elementary {html_document} <html> [ane] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-viii">\n<title>A simple exa ... [2] <body>\n <p>Here is some simple content for this page.</p>\n </body> Let's say that we wanted to store the text contained in the single <p> tag to a variable. In guild to access this text, we need to figure out how to target this detail slice of text. This is typically where CSS classes and ids can help united states of america out since good developers will typically make the CSS highly specific on their sites.
In this case, we have no such CSS, but nosotros exercise know that the <p> tag nosotros desire to access is the merely 1 of its kind on the page. In order to capture the text, nosotros need to use the html_nodes() and html_text() functions respectively to search for this <p> tag and retrieve the text. The lawmaking below does this:
simple %>% html_nodes("p") %>% html_text() "Here is some elementary content for this folio." The simple variable already contains the HTML nosotros are trying to scrape, and so that only leaves the task of searching for the elements that we want from it. Since we're working with the tidyverse, we can just pipe the HTML into the different functions.
We need to pass specific HTML tags or CSS classes into the html_nodes() function. We need the <p> tag, so we pass in a character "p" into the function. html_nodes() besides returns a list, but it returns all of the nodes in the HTML that accept the particular HTML tag or CSS class/id that you lot gave it. A node refers to a betoken on the tree-similar structure.
Once we have all of these nodes, nosotros can pass the output of html_nodes() into the html_text() role. We needed to go the actual text of the <p> tag, so this function helps out with that.
These functions together grade the bulk of many common spider web scraping tasks. In general, web scraping in R (or in whatsoever other language) boils downward to the following iii steps:
- Get the HTML for the web page that you want to scrape
- Determine what part of the page you want to read and find out what HTML/CSS yous need to select it
- Select the HTML and clarify it in the way you demand
The target spider web page
For this tutorial, we'll exist looking at the National Weather Service website. Let'southward say that nosotros're interested in creating our own weather app. We'll demand the weather data itself to populate it.
Weather condition data is updated every day, so we'll use web scraping to get this information from the NWS website whenever we need it.
For our purposes, we'll take data from San Francisco, just each city's web page looks the aforementioned, so the same steps would work for any other city. A screenshot of the San Francisco folio is shown below:
We're specifically interested in the atmospheric condition predictions and the temperatures for each day. Each day has both a solar day forecast and a nighttime forecast. Now that we've identified the office of the web folio that we demand, we can dig through the HTML to meet what tags or classes we need to select to capture this particular data.
Using Chrome Devtools
Thankfully, near modern browsers have a tool that allows users to directly inspect the HTML and CSS of whatever web page. In Google Chrome and Firefox, they're referred to as Developer Tools, and they have similar names in other browsers. The specific tool that will be the most useful to us for this tutorial volition be the Inspector.
You tin can find the Programmer Tools past looking at the upper right corner of your browser. You should be able to see Developer Tools if you're using Firefox, and if you're using Chrome, you tin can go through View -> More Tools -> Programmer Tools. This will open up up the Developer Tools right in your browser window:
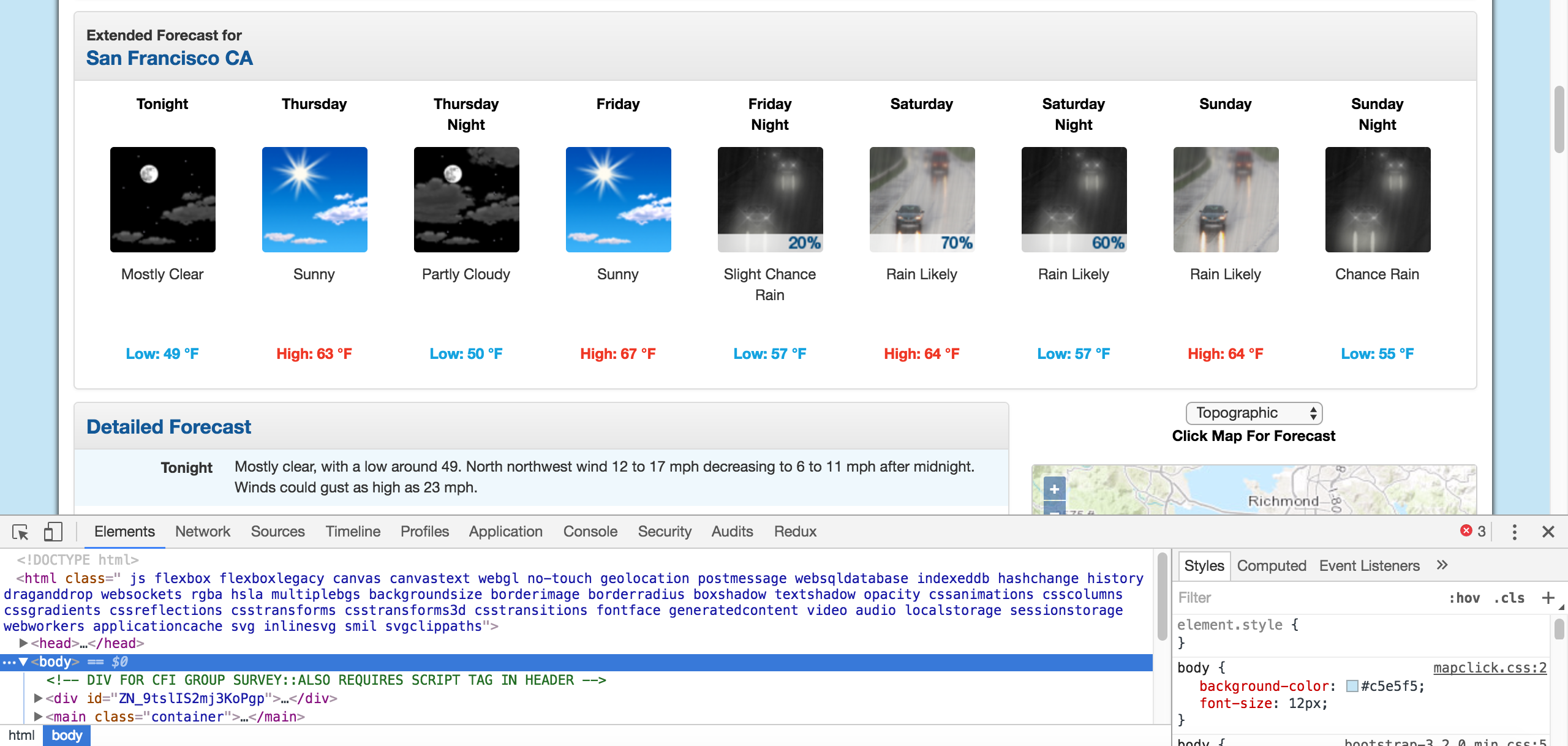 The HTML we dealt with before was bare-bones, but near spider web pages y'all'll see in your browser are overwhelmingly circuitous. Developer Tools will make information technology easier for usa to option out the exact elements of the web page that we want to scrape and inspect the HTML.
The HTML we dealt with before was bare-bones, but near spider web pages y'all'll see in your browser are overwhelmingly circuitous. Developer Tools will make information technology easier for usa to option out the exact elements of the web page that we want to scrape and inspect the HTML.
We need to see where the temperatures are in the conditions page's HTML, so we'll use the Audit tool to await at these elements. The Audit tool will choice out the exact HTML that we're looking for, so we don't have to look ourselves!
 By clicking on the elements themselves, we can see that the seven mean solar day forecast is independent in the following HTML. We've condensed some of information technology to make information technology more than readable:
By clicking on the elements themselves, we can see that the seven mean solar day forecast is independent in the following HTML. We've condensed some of information technology to make information technology more than readable:
<div id="seven-twenty-four hours-forecast-container"> <ul id="seven-day-forecast-list" grade="listing-unstyled"> <li class="forecast-tombstone"> <div grade="tombstone-container"> <p class="period-name">This night<br><br></p> <p><img src="newimages/medium/nskc.png" alt="Tonight: Clear, with a low around 50. Calm wind. " title="Tonight: Clear, with a low around 50. Calm air current. " grade="forecast-icon"></p> <p class="short-desc" way="acme: 54px;">Articulate</p> <p form="temp temp-depression">Low: 50 °F</p></div> </li> # More elements similar the one above follow, one for each day and night </ul> </div> Using what we've learned
Now that nosotros've identified what item HTML and CSS we need to target in the web folio, we tin can utilize rvest to capture it.
From the HTML in a higher place, it seems like each of the temperatures are independent in the grade temp. In one case nosotros have all of these tags, we tin can extract the text from them.
forecasts <- read_html("https://forecast.weather.gov/MapClick.php?lat=37.7771&lon=-122.4196#.Xl0j6BNKhTY") %>% html_nodes(".temp") %>% html_text() forecasts [one] "Low: 51 °F" "High: 69 °F" "Low: 49 °F" "High: 69 °F" [v] "Low: 51 °F" "High: 65 °F" "Depression: 51 °F" "High: 60 °F" [9] "Depression: 47 °F" With this code, forecasts is at present a vector of strings corresponding to the low and loftier temperatures.
At present that nosotros have the actual information we're interested in an R variable, we only need to do some regular data analysis to get the vector into the format we need. For case:
library(readr) parse_number(forecasts) [1] 51 69 49 69 51 65 51 60 47 Next steps
The rvest library makes it piece of cake and user-friendly to perform web scraping using the same techniques we would utilise with the tidyverse libraries.
This tutorial should requite you the tools necessary to beginning a small web scraping projection and kickoff exploring more than advanced web scraping procedures. Some sites that are extremely compatible with web scraping are sports sites, sites with stock prices or fifty-fifty news articles.
Alternatively, you could continue to expand on this project. What other elements of the forecast could you scrape for your conditions app?
Prepare to level up your R skills?
Our Data Analyst in R path covers all the skills you need to land a job, including:
- Data visualization with ggplot2
- Advanced data cleaning skills with tidyverse packages
- Important SQL skills for R users
- Fundamentals in statistics and probability
- ...and much more
There's goose egg to install, no prerequisites, and no schedule.
Tags
Source: https://www.dataquest.io/blog/web-scraping-in-r-rvest/
0 Response to "Read Output of Javascript Script Rvest R"
Post a Comment